我々が目標に向かって行動する際には、二手先、三手先を読んだ行動計画・報酬予測が必要となる。中脳ドーパミン細胞は報酬価値や予測誤差を表現することが知られているが、複数回の報酬獲得を経て目標に到達する場合、強化学習理論が提唱するように、複数の報酬情報を表現するかどうかは不明であった。そこで本研究では、複数回の試行を経て3回の報酬獲得を目標とする行動課題(図A)をニホンザルに学習させ、行動中のドーパミン細胞活動を記録した。期待される報酬の価値を反映すると考えられる、各試行開始の合図に対する応答は、一度も報酬を得ていない試行においては報酬確率に従って増大したが、1回目・2回目の報酬獲得の直後では、報酬確率はほぼ100%であるにも関わらず、減弱した応答が見られた(図2)。このことは、ドーパミン細胞の応答は、目前の1回だけの報酬価値を反映しているのではなく、一度も報酬を得ていない場合には将来3回分の、1回目・2回目の報酬獲得の直後ではそれぞれ2回分・1回分の報酬価値を表現していることを示している。また、このような細胞活動は、課題の報酬獲得スケジュールを習熟してはじめて見られることが確かめられた。以上のことから、ドーパミン細胞の活動は、学習によって長期的な将来報酬価値を表現することが証明された。この結果は、長期的な収益予測に基づいて意志決定や行動選択を行う脳の作動原理解明につながることが期待される。
Enomoto K, Matsumoto N, Nakai S, Satoh T, Sato TK, Ueda Y, Inokawa H, Haruno M, Kimura M. Dopamine neurons learn to encode the long-term value of multiple future rewards. Proc Natl Acad Sci U S A. 2011 Sep 13;108(37):15462-7.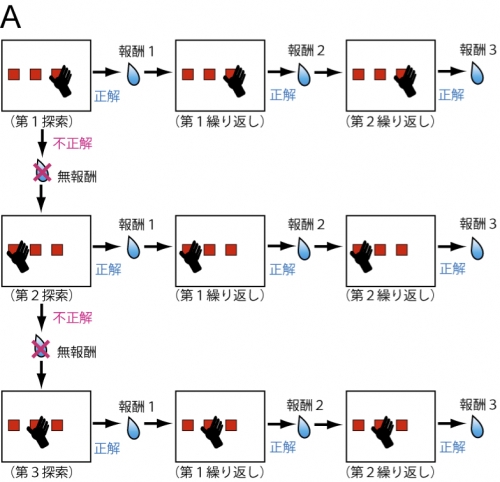
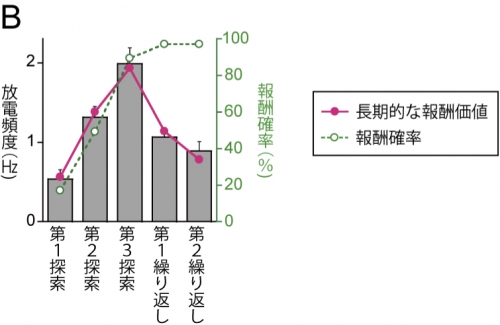
図の説明
(A)動物が学習した行動課題。まず、3つの選択肢の中から試行錯誤で1つの正解を探す(探索試行)。正解ボタンを探し当てると1回目の報酬が得られ、続く2度の試行(繰り返し試行)で同じ選択を行うことで、2回目、3回目の報酬(ジュース)が得られる。動物はこれらの複数試行を経て、合計3回の報酬を得ることを目標として課題を行う。
(B)課題習熟後における、試行開始の合図である視覚刺激に対するドーパミン細胞の応答(棒グラフ)。第1~第3探索試行において、報酬を得られる確率が上がるにつれて活動は大きくなるが、ほぼ100%報酬が得られる繰り返し試行における活動は小さかった。このことは、探索試行においては、繰り返し試行の報酬も含んだ将来3回分の報酬価値を、第1繰り返し試行においては2回分、第2繰り返し試行においては1回分の報酬価値が表現されていることを示している。折れ線グラフは、強化学習理論に基づいて推定した、長期的な報酬価値(実線)と各試行での報酬確率(点線)。