Assigning long-term reward value for actions is a learned intelligence for a successful achievement of a distant goal. Although midbrain dopamine neurons are known to signal reward value and its prediction error, it is not examined experimentally whether and how dopamine neurons encode long-term value of multiple future rewards, as suggested in reinforcement learning theories. We address this issue by studying 185 dopamine neuron activities recorded from three monkeys that performed a multi-step choice task for three rewards. In the task, they explored a reward among three alternatives and then exploited this knowledge to receive two additional rewards by repeating the same choice in subsequent trials. Duration of anticipatory licking for reward water represented expectations of multiple future rewards; the sum of immediate and discounted future rewards. In accordance with this result, dopamine responses to the start cues and reinforcer beeps reflected the expected values of the multiple future rewards and their errors, respectively. These responses were quantitatively predicted by theoretical descriptions of the value function with time discounting in reinforcement learning. Moreover, we confirmed that these responses were established through learning the multistep choice paradigm for rewards. These findings demonstrate that dopamine neurons “learn” to encode the long-term value of multiple future rewards with distant rewards discounted. (Proc Natl Acad Sci U S A. 2011 Sep 13;108(37):15462-7)
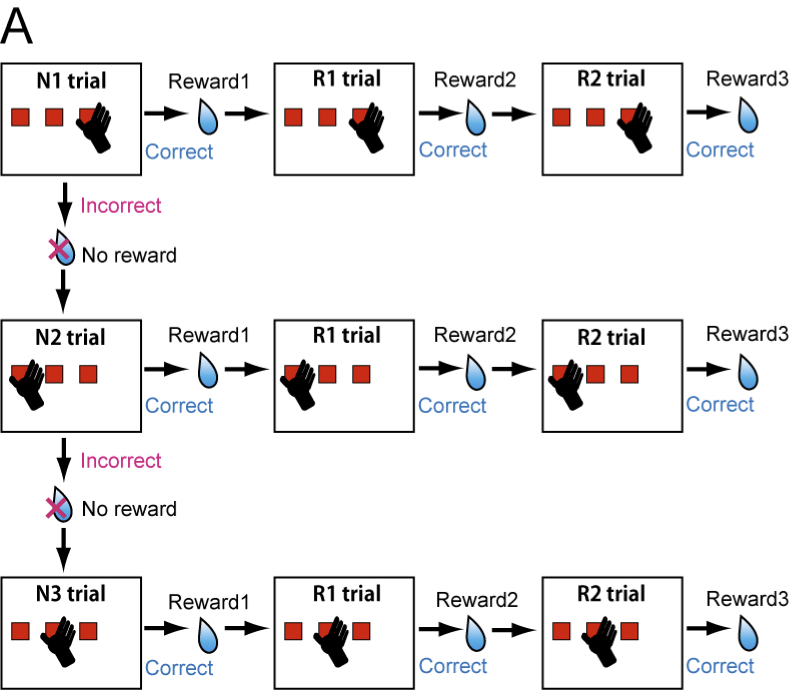
Figure legend
(A) Schematically illustrated structure of the three-step choice trials to obtain three rewards at different times. The monkeys first explored three targets to find the rewarding one (N1-N3 trials) and exploited this knowledge to get two additional rewards by choosing the same target (R1, R2 trials).
(B) Bar graphs of ensemble average of dopamine responses (mean and SEM) above the baseline. The best-fit value functions estimated as the TD error in reinforcement learning theories (solid red line) and reward probability of trials (dashed green line) are superimposed.
* Brain Science Research Center, Tamagawa University